Author of paper: Xiangyu Zhang, Xinyu Zhou, Mentxiao Lin, Jian Sun
Abstract
ShuffleNet: designed for mobile devices with very limited computing power.
The new architecture utilizes two new operations:
-
channel shuffle
-
pointwise group convolution
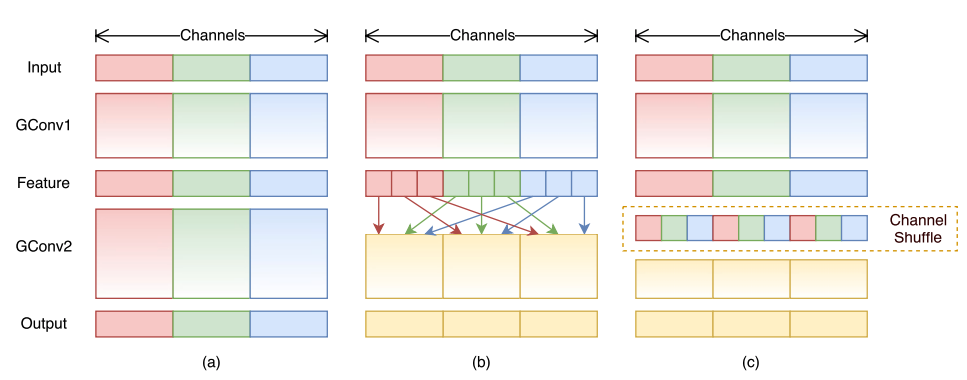
Channel Shuffle
Group Convolution
GConv was first introduced in AlexNet for distributing the model over two GPUs, which can reduce FLOPs.
inputChannel = 256
outputChannel = 256
kernelSize = 3 * 3
numsofParams = 256 * 3 * 3 * 256 = 589824
group = 8
# input channel of each group = 32
# output channel of each group = 32
numsofParams = 8 * 32 * 3 * 3 * 32 = 73728
Side Effect:
Two stacked convolution layers with the same number of groups, each output channel only relates to the input channels within the group, no cross talk.
This property blocks information flow between channel groups and weakens representation.
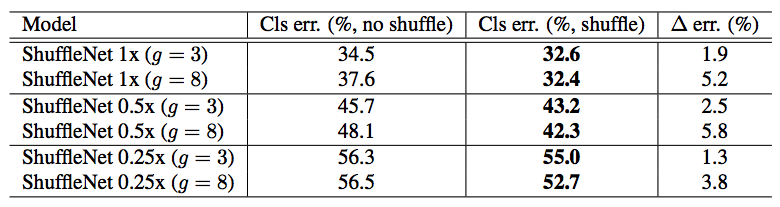
Channel Shuffle
Input and output channels are fully related when GConv2 takes data from different groups after GConv1.
The left one is an equivalent implementation using channel shuffle.
Pointwise Group Convolution
Depthwise Separable Convolutions
inputChannel = 256
outputChannel = 256
numsofParams = 256 * 3 * 3 * 256 = 589824
# DW
# 1 * 1 * 64 filter
# 3 * 3 * 64 filter
# 1 * 1 * 256 filter
numsofParams = 256*1*1*64 + 64*3*3*64 + 64*1*1*256 = 69632
Vanishing Gradient Problem

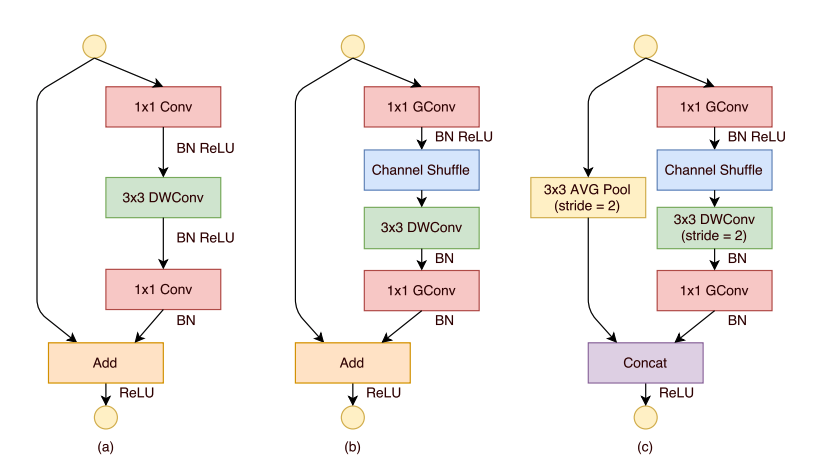
bottleneck unit & ShuffleNet Unit
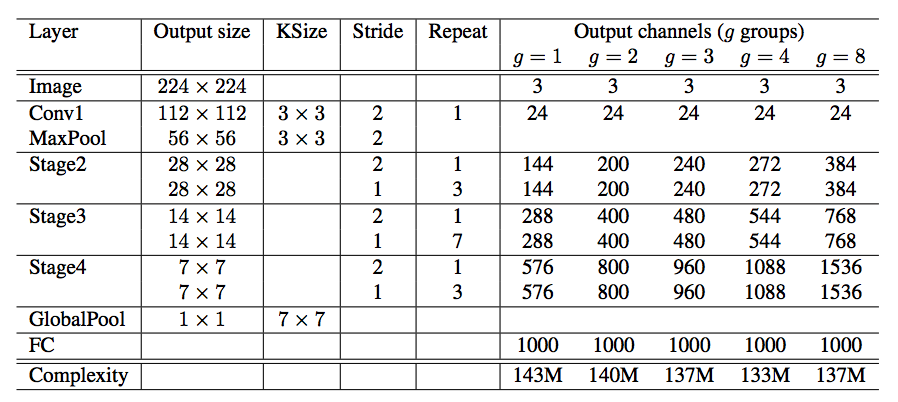
Network Architexture
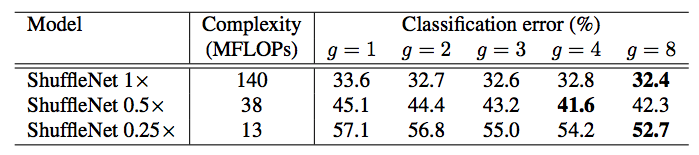
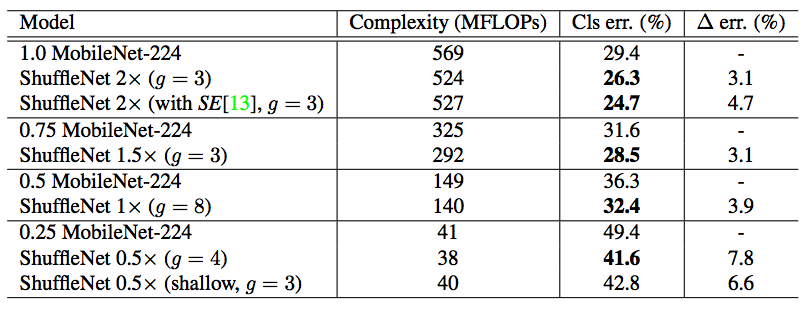
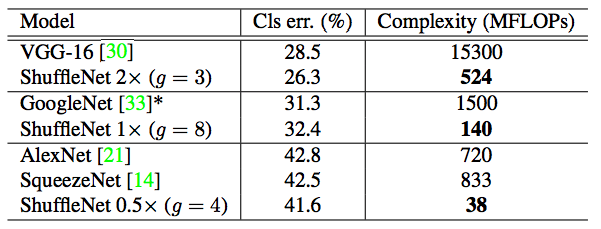
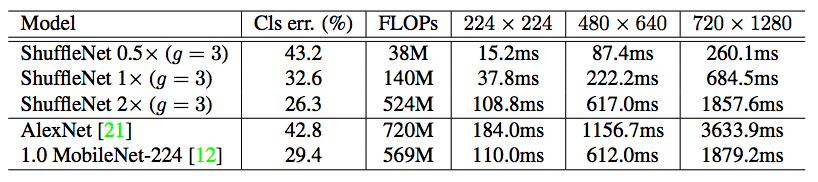
Experiment